自从8月底飓风算法3.0上线之后,仅仅过了20天,也就是2019年9月18号,百度就发布了一则搜索违规处理情况通告,其中处理掉528万个恶劣采集网站。相信很多站长是欲哭无泪。
中国这个大环境就是浮躁,很多做SEO的都喜欢吃快餐。火车头、DEDECMS采集程序大行其道,伪原创工具也搞的有模有样。但是飓风3.0之后,如果不改变采集方式,当真是越采集死得越快哦!

很多站长没有意识到事情的严重性,一些有智慧的人(SHA)(HAI)(ZI)还有模有样的搞纯采集,某些牛掰站长信誓旦旦的跟码迷说,老子的站照样收录没问题,老子的算法能过百度原创检测,老子有伪原创工具很。你也不看看你站收录的是有500w,但有排名的指数词有几个?一周内收录还有几个呢?

采集站下去,原创站上来
你的采集站下去了,人家做原创的上来了,码迷有个合作的站点Duang的一下子涨了一倍的词库,窝草,幸福来得那么忽然,哈哈哈哈嗝。

百度好歹也是养着一群985、211的程序猿,虽然大搜的那帮人算法垃圾,但经过百度的三代原创检测系统的升级,绝大多数伪原创手段到目前都已经没有了效果。但不等于就没法做采集了,也不等于没法做伪原创哦。码迷觉得飓风算法3.0也没有那么高深,道高一尺,魔高一丈哦。
某些采集站仍然有排名
同样是采集,同样是伪原创,有的人发100篇,被百度干100次。而有的人发100篇,都能进入百度重要索引,而且指数词都有了。
比如下图这个案例,采集加工也是优质内容,而且是首页排名哦。
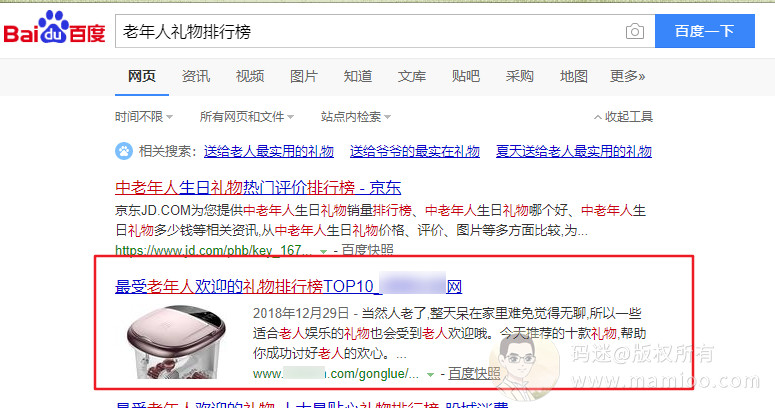

今天我讲为什么你通过采集发的文章没有排名,没有收录,甚至被K站。有些大神认为是运气,哈哈哈哈嗝。很多人不知道所以然,往往是因为自己根本就不知道百度飓风是什么玩意。
已知无用的伪原创手段
《SEO实战密码》 中总结了6种内容作弊手段,这些都已经被百度识别了。无论是同义词替换还是简单在原来文章上做更改,都已经没有收录的几率。其中已经没有用的伪原创手段包括如下:
1 更改(完全重写)标题
2 颠倒段落次序
2 加一段原创,如在最前面加一段内容摘要
3 文字简单增减,如感叹词、修饰词
4 同义词近义词替换
5 强行插入关键词,如在一篇小说中强行插入关键词
如果说作为黑帽SEO高手的你还用以上这些手段,放下屠刀立地成佛吧,该干啥的干啥去,别浪费时间。
为什么同义词替换没有用?
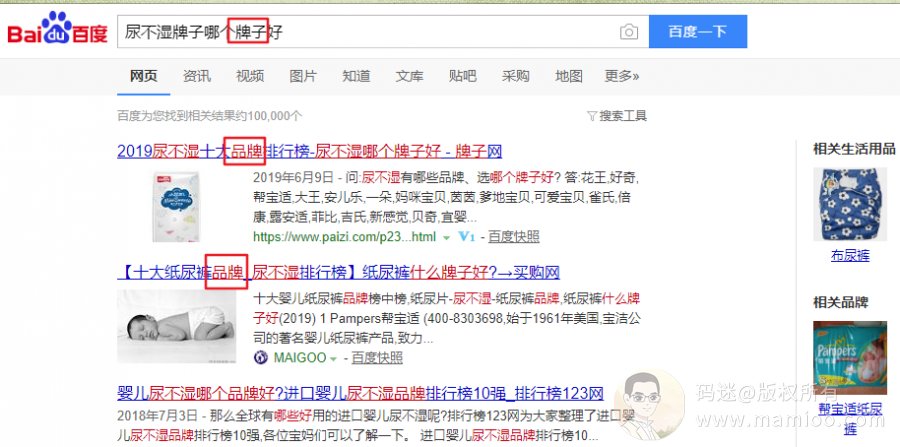
这块百度已经说了百度有自己的同义词库了,还有人做伪原创光用同义词替换,尤其是某个站长工具站也推出了同义词替换工具,名曰智能伪原创。智能个毛啊,你比百度智能??
比如你再百度搜索xx牌子好的时候,品牌也会飘红。
AI伪原创
本来不敢写AI伪原创方面的评测,害怕会得罪某些人,但是码迷找了几个圈子里面用伪原创的站长,反馈飓风3上线后,收录是一天不如一天,比如今天发1000篇伪原创文章,下午就剩下收录500篇,明天收录收录不到100篇,90%以上伪原创内容的都被百度识别掉了。
如下图左边是原文,右边是AI伪原创的结果,可以看到无论是句子顺序还是很多词语,都发生了变化。基本每个句子都不是相同的。最近很多人都热推AI伪原创,认为可以通过百度收录,可以取得排名。
嗯嗯嗯AI伪原创好,专注于采集的老王站长觉得自己已经打通了筋骨脉络,终于可以大干一场了。

然后码迷直接问了做智能伪原创的卖家有没有过百度的案例,然后被他喷了,被他喷了。。。“我欠你的吗”?

江湖上流传的SEO指纹算法
码迷偶尔看到《某某SEO:搜索引擎是如何识别内容原创的?独家揭秘SEO指纹算法!》,感觉很有道理的样子,出处在哪里?如果是自己编的,这里省略100字。
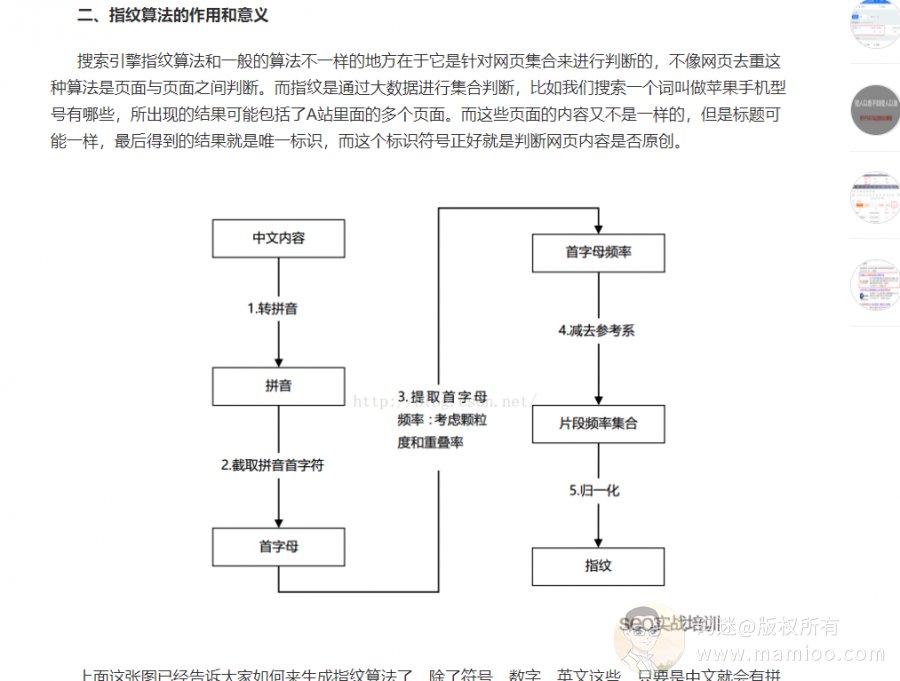
百度3代伪原创识别系统
SEO高手跟小白的区别是什么?就是知其然知其所以然。码迷见过太多自以为的站长被自己打脸了,这还没有轮到百度打脸。不知道原理就开始瞎搞,有个毛线效果。来吧,跟码迷一块深入飓风算法吧。
第1代百度原创识别手段:
根据《CN201110031636-一种网页重复的判断系统及其判断方法》专利,这是2011年左右的老专利了,可以说是百度第一代伪原创识别系统。主要手段是通过对网页结构化数据做simhash。

通过这种识别手段,采集来连标题都不改正,正文也不修改的,基本没戏了。
主骤如下:
在本实施例中,进行网页重复的判断时,如果两个网页满足任意一项,则认为这两个网页是真重复 :
1、两个网页的真实标题签名相同。
2、两个网页的网页内容签名相同。
3、两个网页的网页正文签名的不同位数小于 6。
4、两个网页的网页位置签名相同,并且 url 文件名签名相同。
5、评论块签名、资源签名、标签标题签名、摘要签名、url 文件名签名中有三个签名相同。
缺点:
这个算法要对网页五个维度走签名计算,码迷觉得这个算法计算量太多了,估计百度试用了一段时间就放弃了。
另外修改一个字签名就不一样了,很容易破。
第2代百度原创识别手段:
很多人说“baidu就是个垃圾”,码迷觉得很有道理。码迷说了第一代计算量太大了,耗费钱啊,毕竟竞价排名才挣钱呀,自然排名搞这么高大上的去重算法干啥,艳红不喜欢。那怎么找个最简单的办法去重?
百度程序猿如是说:
咱们从整个网页中,提取出一个最长句子,根据提取出的最长句子的签名进行分组,同组内根据title的皮尔逊距离(计算网页内容的相似度)和链接发现时间进行原创性网页的识别,即判断同组内谁是真正的原创。

优点:
该原创度识别方法码迷推测应该存在了很长很长时间,这种方法优点计算量小小的哦。
缺点(硬伤啊):
仅仅通过最长句子作为依据,误判率相当高。
第3代百度原创识别手段:
因为第二代的手段效果很不好,所以百度终于推出了飓风算法( 2017年7月7日上线),而对应的专利在2017年3月底提出的申请,那么时间点也比较吻合。基本思想是对句子使用simhash算法做签名,然后用汉明距离做原创度检测。

什么是同义词级别simhash
看不懂没关系,先了解simhash算法一点皮毛,码迷简单举一个例子,一图胜千言。
如果您是算法专家,可以访问传送门:https://github.com/yanyiwu/simhash了解simhash算法。

AI伪原创能过百度原创吗?
基础假设
那么回到AI原创的问题,因为百度飓风3.0按照句子级别的simhash进行去重,我们假设:
前置条件1:对句子长度为100个字,进行伪原创
前置条件2:把句子的签名做对比,伪原创后编辑距离位数小于10,并且汉明距离小于10,并且汉明相似度大于80%
判定结果:抄袭
百度内部肯定有自己的汉明距离临界值,100个字符的句子已经是很长句子了,实际中百度的汉明距离临界值应该更小,我们上面假设中的已经相当宽泛了。
不了解编辑距离,汉明距离(也叫海明距离)的可以看
百度百科《编辑距离》:https://baike.baidu.com/item/%E7%BC%96%E8%BE%91%E8%B7%9D%E7%A6%BB/8010193?fr=aladdin
百度百科《海明距离》:https://baike.baidu.com/item/%E6%B5%B7%E6%98%8E%E8%B7%9D%E7%A6%BB/4235876?fr=aladdin
你不会编程没事,码迷会。码迷有现成的分词方法,也有停止词过滤程序,直接用github上的程序。
参考:https://github.com/cmhc/simhash/blob/master/src/simHash.php
码迷随便找了一篇网易的文章,做一下simhash的编辑距离跟汉明距离。
AI伪原创工具评测1:

最终结果:
没有过假设的百度原创关,编辑距离为6,海明距离为8,相似度高达87.5%

AI伪原创工具评测2:
码迷不死心,又要了另外一家AI伪原创:

最终结果:
没有过假设的百度原创关,编辑距离为7,海明距离为10,相似度高达84.3%

AI伪原创工具评测3:
码迷还是不死心,又要了另外一家AI伪原创:

最终结果:
他xx的什么破AI伪原创,编辑距离只有4,海明距离为6,相似度高达90%!被百度干的都不剩,别误人子弟好不好?

结论
首先、直接伪原创不容易过百度原创
人家百度几千号人来做开发呢,就凭一个伪原创就能过了百度检测吗?所以大家千万不要直接采集人家的内容,稍微伪原创就发到自己网站上了,这就是作死。
其次、同义词替换语句颠倒没毛用
某些网站声称几十万的同义词近义词词库,码迷告诉大家,百度为了压缩索引,同义词词库可比你们任何词库都丰富的多,人家的同义词库还是分词性的。另外语句颠倒不会影响simhash算法结果哦。
如何做采集过原创
但是人家有些人靠采集就能做出排名了,这是为什么?有些人靠采集组合也能有排名,即使不用上伪原创就能上百度排名。码迷一个合作伙伴网站,还没起来就被飓风算法打的都不剩了,但是经过码迷研究,让其更新采集组合算法之后,又恢复了往日的精彩~

下一篇文章我们将讨论如何才能通过采集过百度原创判定算法,因为毕竟是不断的投入研究实验花费了大量精力,所以码迷将在通过码迷官方群734299959,通过群直播的方式带你走进百度飓风算法3.0的倒戈之旅。
 百度飓风3原创检测算法讲解以及伪原创检测工具")




")
网站秒收策略:基于时效性算法促进内容快速收录")
【硬货】快排难度升级:谈谈指纹识别算法的破解")
评论列表 (0)