大家好,我是mamioo的站长,大家可以叫我码迷,80后,大学毕业的时候是物理专业,机缘巧合转入计算机互联网行业,10年老码农。 懵懵懂懂做SEO六七年的样子,在做SEO的时候,外链数量和类型都是有工具。但是码迷咨询了很多SEO同行,至今未找到令人称心的关键词布局工具。
大家做完内容,即使是原创的长尾,也没有100%的把握拿到百度首页的排名。网站内容质量上,目前国内还没一个专业SEO评分工具(至少我没有发现,有则请告知)。

17年底受到国外Matt《TF*IDF for SEO》这篇文章的启发,码迷开始萌生开发摩天楼工具的想法,打算开发一套SEO内容层面可靠的可量化的评测工具。
目前摩天楼主要的底层算法是相关性算法,到现在更新迭代3个版本,几乎每个版本都是重构代码一半以上,并且还要做海量的数据采集加工来验证算法的准确性。
摩天楼内容助手码迷觉得非常好用,码迷实战操作中,都是百度谷歌双首页的案例。我觉得做科学的事情,终究离不开科学唯物的验证方法,离不开探索本质的毅然决心,离不开百万级的数据分析,更离不开最新最前沿的算法应用和神经网络训练吧。
PS:
因为码迷是物理系毕业,潜移默化的习惯运用物理方法(如控制变量法,逆向推演算法本质,归纳总结事物各部分之间内在的本质的必然的联系)。
进入正题啦:
本文主要内容是讲述摩天楼内容助手底层算法细节以及开发过程,以及讲述科学研究中一些常用的方法。
摩天楼内容助手主要2个部分组成,定制版的TFIDF(BM25)搜索系统+小型的ML集群。主要的人工智能算法包括(TFIDF\BM25、余弦相似度),以及开发过程中两个常用的软件方法(控制变量法、黑盒测试)。
希望能为研究SEO行业的同僚们,提供一个破解排名难题的思路。如果你有任何疑问和建议,码迷期待与你交流经验。
Part1. SEO的排序因子
SEO最核心的问题是排序问题,看一些数据跟培训课程,都认为搜索引擎一般通过三个大方面来决定网站的排序:
- 内容质量(相关性、语句通顺、字数等)工具:排版工具、伪原创生成
- 信任度(域名、外链、持续产出等)工具:juming\aizhan\5118等
- 用户体验(UI体验、加载速度、留存、访问时长等)工具:17ce\cnzz\百度统计
Part2. 资料搜集
为什么现在国内市场上可量化的SEO内容方面的工具为什么一个也没有?码迷认为因为搜索引擎是黑盒,大家不知道搜索引擎怎么对内容打分,或者是这个问题好难,导致都没有思路。
搜索引擎怎么对内容打分? 因为我之前只看过SEO手段类的书籍,如昝辉的《SEO实战密码》,搜索底层的东西知之甚少。
那就找资料去吧,花了1个月时间翻阅了几乎百度所有搜索相关的专利(漫长的分析问题的过程),发现百度是基于内容相关性排序的。
问题很明显:搜索引擎如何按照相关性排序?
Part3. 问题&验证思路
当时我解决问题的思路是这样的,目前也是一直遵循的这个思路
第1步: 构建SEO内容质量排序算法的最小化版本
第2步: 准备100个左右目标关键词
第3步: 使用爬虫系统采集目标关键词的前10页的搜索结果 作为验证集以及训练集
第4步: 使用自建的SEO内容质量排序算法对验证集排序
第5步: 判断排序结果重合度即可。也就是自己的排序结果的TOP10与搜索引擎的TOP10的交集占比。
Part.4 落地过程
4.1 相关性算法TFIDF
使用过搜索引擎的人都知道,其搜索结果不一定是完全符合所有查询之关键词,也可能是部分相符,搜索引擎会将符合程度愈高的结果排在愈前面。
当然,如Google 之类的搜索引擎,还会搭配其他的因素,来决定搜索结果顺位。不过,基本上,还是以相符程度为主要的基准。

有兴趣的小伙伴可自行去看TF-IDF的资料,TF-IDF的公式并不复杂,18年初摩天楼最小化验证版本经过2天左右开发完成,TF-IDF函数也就50行代码而已。
4.2 黑盒测试&控制变量法
搜索引擎作为一款黑盒产品,我们不知道他底层的各个因子是怎样的逻辑,但是可以通过控制变量法一点一点的试验测试。
我们知道搜索排名的因素有域名、外链、内容主要这三部分决定排名,我要研究的是内容方面,那么尽量把域名外链的干扰因子降到最低。
我的当时的步骤是这样的(其实这一步失败了,也耽误了很多时间)
步骤1:准备5个新域名 lkdak1.infolkdak2.infolkdak3.info lkdak4.info lkdak5.info,这样这些域名年龄一样,并且没有外链。
步骤2:每个域名都做单页站点,内容中包含一个核心词【叉黑去八】,以及【看匹后空】、【思哈璐腾】等20左右个相关词。注意,这些词都是未曾出现过的词语,所以在搜索引擎的语料里面底子也是干净的,在内容中用成对的符号括起来防止分词。
步骤3:规划5个站点的内容,标题中均含有核心词,控制相关词的出现顺序,同时提交百度跟谷歌站长后台。
步骤4:等待,等待,稍安勿躁,等百度、Google收录倒排之后,搜核心词看看是否符合TFIDF算法计算出来的预期排序就行了。
4.3 不干净的百度
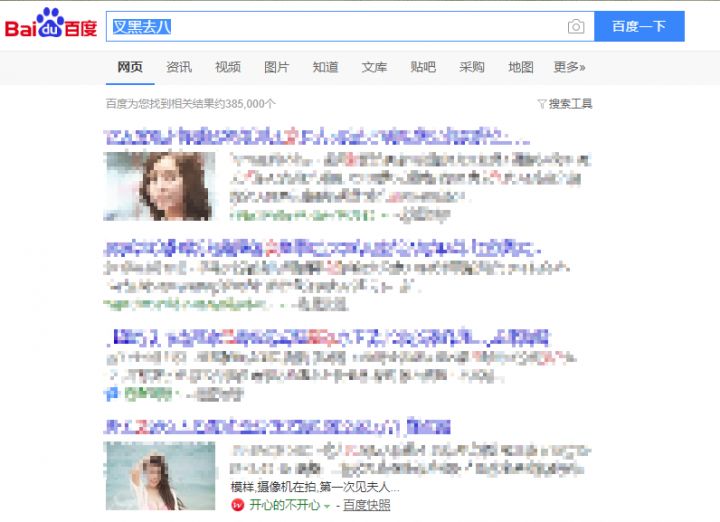
想法是好的,但是现实很骨感,码迷18年3月左右上的网站,百度3个月才收录。但是在百度上搜"叉黑去八",我不明白百度为啥这么不务正业,百度工程师天天干啥?!
谷歌中也是搜索不出来,即使通过搜带双引号的核心词能出来,也跟预定的TFIDF排序结果并不相符。
第一轮验证以失败告终。其实这一步主要原因是过度参考Matt的思路,中文英文分词方式真的不一样。
4.4 移步谷歌验证
18年7月份左右一直断断续续等着百度收录,查看排序结果,但是通过控制变量法并没有太多的进展预期。反而这时候让我认彻底清了百度,态度不端正就算了,百度排序算法中人为干扰的因素实在是太多太杂了(估计一切向钱看)。
第二轮验证中我直接抛弃了百度,决定使用谷歌。原因有两点,一是谷歌没有快排干扰,二是谷歌界面清爽没有乱七八糟。
这次验证不再使用【叉黑去八】这类无意义的词语,使用了略微接近自然语言的无搜索指数词语,如"麦动猪"。这些词有几个特点:
第1:无时效性分值、地域性分值,比如“天气”都是非常受地域时间影响的
第2:容易产生分词效果,如果重复的次数过多,搜素引擎就认为"麦动猪"是一个词了
第3:在谷歌上搜没有完全匹配query的结果集
4.5 语料系统升级
因为单页站点的内容过少,以及产生分词效果不理想,所以借鉴了泛目录的一些程序思想生成海量数据:
第1:使用了100万左右的断句作为随机语料(之前做母婴的时候,采集过雅虎的数据可以现成用)。
第2:每个域名1000篇文章左右,文章标题均含有"麦动猪"目标关键词,标题中按照一定的布局密度布局相关词。
第3:随机挑选200个左右的语料句子组成一篇文章,文章中按照一定的布局密度布局相关词,保证文章长度统一为3000字左右。
网站重新上线后,这里不得不佩服谷歌的收录速度,基本上1个月左右内容均能收录,再索引的周期在4天左右。相反通过监控百度爬虫类型,内容变更到索引变更短则两周,长则无限期。
18年9月的一天,在谷歌上搜索"麦动猪",忽然发现排在前面的文章有自己名下的域名的文章了,好一波欢心。
4.6 摩天楼(Beta1)第2轮验证
到了验证的时刻,使用自建的SEO内容质量排序算法对验证集排序。思路是简单的拿搜索引擎的排序结果与自己算法排序结果做对比。

假如说
谷歌的首页结果是:A B C D E F G H I J
我的结果是: B C D W L X H E F Z
共同的部分是:B C D E F H
10个结果里面有6个是重复的,那就是重合度在60%;
不过很遗憾,通过谷歌给的搜索结果与自己TF*IDF算法排名的重合度在10%左右,也就是只有一个域名能上到第一页,其他域名原因不详。当时分析的原因有3个:
原因1:谷歌对随机生成的文章能感知出来(现在也不确定)。
原因2:TF*IDF算法不是主要算法。
第二轮验证也失败了。
基本上这个状况持续到18年深秋,正如这时候风卷残叶的场景,感觉投入了很多时间以及学习参考了海量的资料,最后竹篮打水一场空了。
Part5. 她的点拨
18年10月底左右,同学从美国留学回家探亲(其实是3年没回家,母亲忽然离世了),正好是大数据相关专业的博士,主攻Machine Learning图形诊断方向。
事到如今我只能死马当作活马医,试探的问了一下姚博士是否了解TFIDF算法,人家说这是最基本的。。。然后我就把我这半年的开发过程跟想法说了一遍,博士然后给了大概这么2个建议:
建议1:随机生成的文章会造成相关性主题偏离,需要用聚类算法做诊断。
建议2:TFIDF算法是比较固定,是很老的算法了,不支持附加参数调优,建议用BM25。
不知道大家能不能跟上,反正码迷是google一个下午才茅塞顿开。
第二轮验证失败的原因:
原因1:使用泛目录程序生成的文章不合格(需要做质量控制)。
原因2:谷歌对TF*IDF算法有特定的参数和实现。
5.1 聚类算法
如果你发一篇文章题目是“猫粮推荐”,内容却是主要讲“怎么给小猫喂食”的,这就是主题不相关。百度收录没有问题,但是在倒排索引的时候,过不了主题集中的关卡(因为文章聚类得分偏离太大,直接剔除了)。
聚类算法码迷用的是大家都知道的余弦相似度。
5.2 升级版的TFIDF=BM25
TFIDF算法是一个可用的算法,但并不太完美。它给出了一个基于统计学的相关分数算法,我们还可以进一步改进它。
科普PS(大牛们可以不用看,啰里啰嗦):https://blog.csdn.net/northhan/article/details/50952728
5.3 摩天楼(Beta2)
摩天楼码迷基本上做了全局的重构,包括如下几点:
点1:自行实现了BM25算法(因为github上PHP的没几个,还写的很烂,只能自己动手了)
点2:随机组合的语料文章,分词之后,通过检查TF TOP10,检测是否词频过高,来保证文章主题集中
点3:搜集了100个真实目标搜索词,采集了谷歌结果TOP100作为训练集(因为需要BM25参数范围,机器学习部分外包给你了一个北京的前同事,玩的是TensorFlow)
不过因为算法升级,加上新引进的ML集群,这个成本是居高不下了,服务器由原来的2台(一台国内,一台香港),变成了现在的9台,家底要掏干了啊。
Part6. 科学验证
花了2个月左右紧张开发,18年年底算法终于升级完毕,文章也修正了,同时并行的ML训练脚本进展还算顺利(主要卡在采集谷歌的时候老是弹出人肉验证,不知道谷歌用的什么高科技)。同时北京前同事的训练结果也出来了,提供了宝贵的三个参数(k,b,文档数)。
那么接下来就是验证效果,为了保证验证的准确性,科学性,码迷主要从3个方面来验证摩天楼相关性算法的准确性。
验证1:对自定义语料内容(5个.info域名内容排序验证)(正面验证)
验证2:另外准备100个自然搜索词,验证新相关性算法的排名与实际排名的重合度(反面交叉验证)
验证3:做3-5个严格按照摩天楼指导意见规划内容的网站,看是否能排名到首页(实战验证)
6.1 验证1 结果:
整体来讲,自己做的语料计算的排序结果跟谷歌的排序结果重合率不高,最多30%左右,目测谷歌对随意拼凑的内容真的不友好。不过发现1点数据,侧面印证了谷歌排序与TFIDF有关:
同一网站中(域名权重相同、外链相同),在Google中内容相关度高的更靠前。
6.2 验证2 谷歌结果
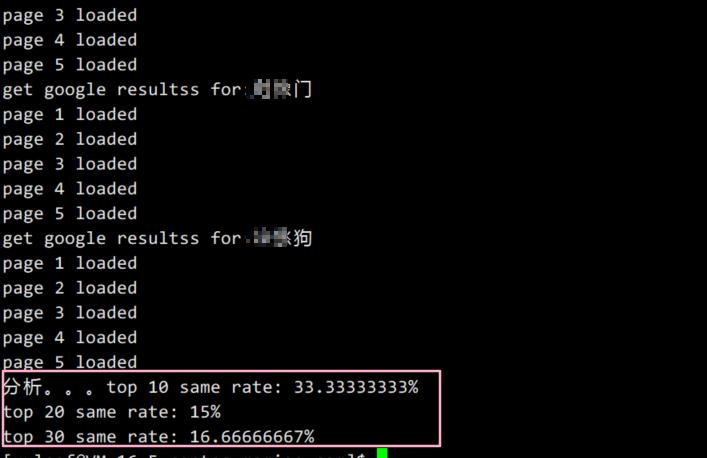
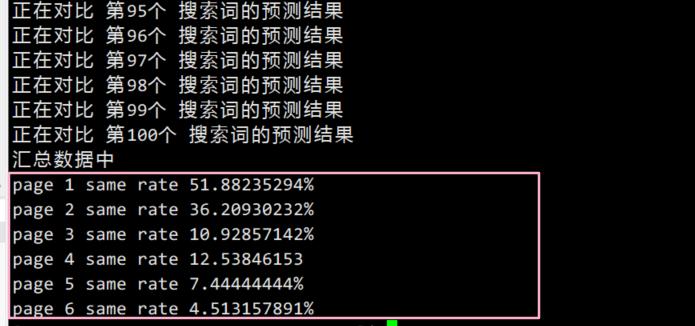
验证2方法是反面验证跟正面验证相结合的方法,码迷使用了另外100个自然搜索词,采集谷歌的TOP100文章结果作为训练集,使用摩天楼的相关性排序方法排名后,再跟谷歌的排名结果做对比,验证新相关性算法的排名与实际排名的重合度。
首页50%的命中率!谷歌还是内容质量至上。而且从衰减趋势上看,谷歌衰减很匀称很稳健。
6.3 验证2 百度结果
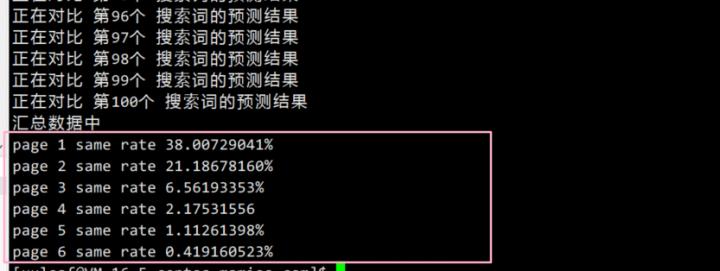
搞了谷歌,同一套程序,可以再验证一下百度的排序。
38%左右的命中率,也侧面印证了百度排序算法使用了相关性算法,只是比率比谷歌低10%。
不过大家仔细看百度的结果有个特点,从首页排名到第三页的命中率衰减很快,首页38%,第二页21%,然后第3,4,5,6页都是个位数了。大家想想为什么百度衰减如此之快?
我是这样认为:内容相关度是进百度前30的敲门砖,如果你的网站内容相关度超过某个阀值,百度排名会有特殊优待。而达不到阀值,就容易受其他因素干扰,造成排名不稳定。
重点来了,一旦你的内容相关度到一定程度,你的排名就稳如狗了。
6.4 结论
上面两步的验证结果我们可以得出以下3个结论:
结论1:搜索引擎确实是按照相关度排序的
结论2:谷歌相关度排序打分占总比50%左右
结论3:百度相关度排序打分占总比38%左右,比某快排说相关度占3成得分要高一些
结论4:通过百度衰减趋势我们可以认为,相关度越厉害,首页排名越稳定

Part7. 实战验证(百度谷歌双排名!)
开发摩天楼的文章质量评分、相关词建议功能在今年1月份紧张开发,于2月份正式实战内测。如果用非指数词做排名,就没啥意义了,码迷就选了2个指数都超过200的目标词。
结婚礼物 百度指数300左右,
实战案例具体请见:[结婚礼物]指数300+新站45天排名第2-百度谷歌双首页
生日礼物百度指数1000左右,
实战案例具体请见:[生日礼物]1000+指数词50天上百度+谷歌首页
Part8. 以上
码迷第一次写这么长的技术文章,不知道大家有没有看懂。码迷还是重复文章开头的话,摩天楼内容助手之所以有效果,离不开科学唯物的验证方法,离不开探索本质的毅然决心、离不开百万级的数据分析、更离不开最新最前沿的算法应用和神级网络训练。好的产品值得你投资。








评论列表 (0)