今天开始探讨正式内容的第一讲了,开始讲百度蜘蛛。今天针对广泛流传的百度蜘蛛IP类型做一下探讨。咱们知道,知识零散的点,经验是点的连线。所以大家在学习的时候养成大局观,比如说,我们现在在这个位置。
关于码迷:
7年SEOer,摩天楼内容助手作者,专注SEO算法研究,QQ2027725943,欢迎志同道合的盆友加我交流。
探索方法
码迷通过对7个网站的爬虫日志做追踪,将百度蜘蛛分为收录蜘蛛、首页收录蜘蛛、快照蜘蛛三大类。
码迷用控制变量法,通过现象看规律,通过规律看本质,通过本质讲对策。
通过线上实验来一步一步做验证推导过程。
百度蜘蛛类型有哪几种
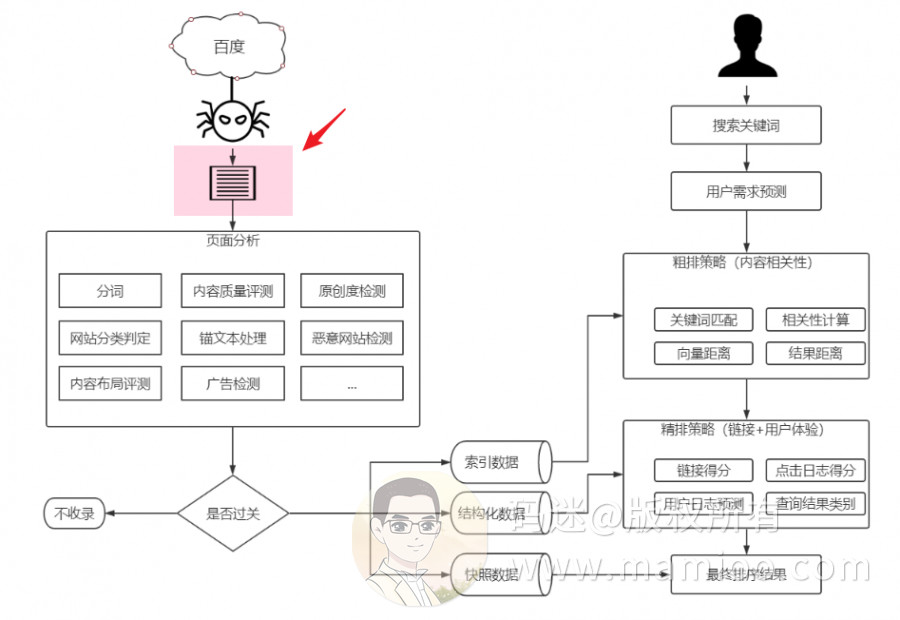
下图是网上广泛流传的百度蜘蛛IP类型说明,其中123开头的认为是降权蜘蛛,220开头的一般认为是权重蜘蛛。

下图是某站长工具提供的蜘蛛日志分析工具,也是将百度蜘蛛分为高低权重之分。
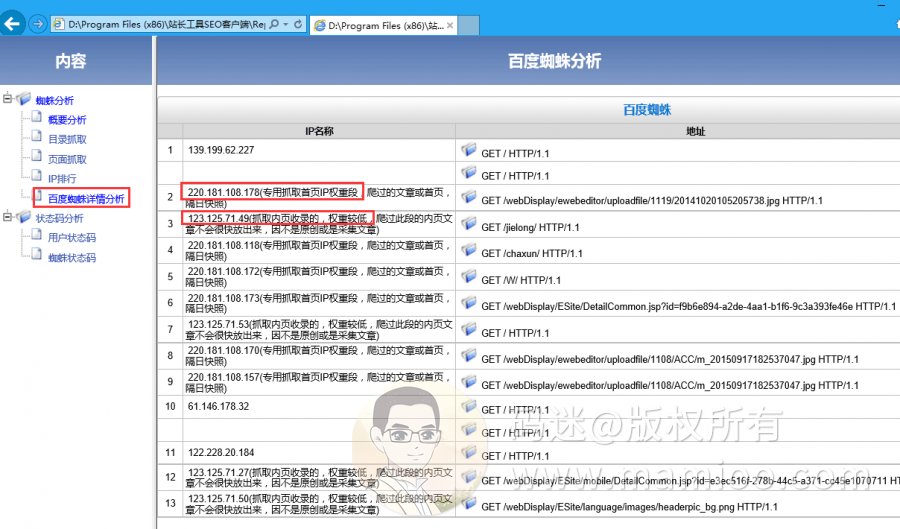
到底有木有降权蜘蛛
看了百度站长的平台的回复(年代比较久远),百度官方回复是“没有”。
http://bbs.zhanzhang.baidu.com/thread-6387-1-1.html
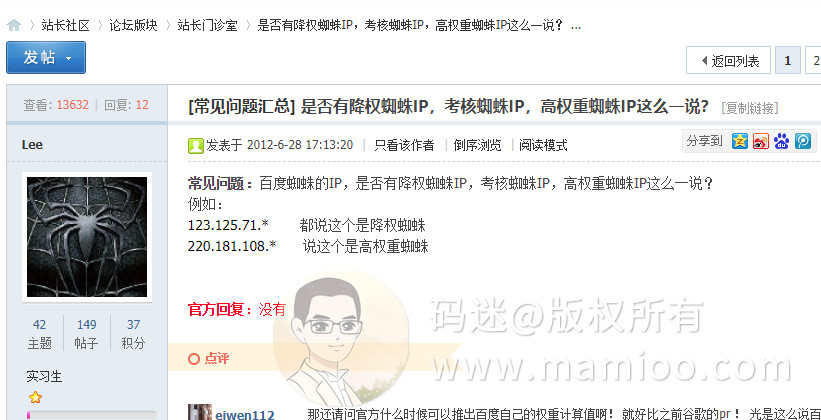
码迷也认为蜘蛛没有权重高低之分
为什么分降权蜘蛛、权重蜘蛛之说?
如果蜘蛛有权重高低之说,难道百度一开始就知道你的网站质量吗,码迷觉得一脸懵X,百度蜘蛛你真NN的可以,都能未来了。

百度蜘蛛分类的猜想
百度爬虫是干什么的,就是把你的网站页面内容扒下来,然后把数据拆分为标题、摘要、头图、正文等结构化数据,放到百度的数据库里面,提供给用户搜索。
但是网页数量以百亿计,每个页面都有快照备份是不现实的。
码迷大胆猜想,百度蜘蛛应该有功能之分,并未高低权重之说。码迷(网站www.mamioo.com)把百度蜘蛛的爬虫日志存放到数据库里面,进行分析追踪。看到了几个现象,我们再总结规律,探讨本质。
现象1:内页爬取规律
新上的某个网页的爬取记录,我们可以看到,通常都是123开头的蜘蛛先行,然后220开头的蜘蛛后行。
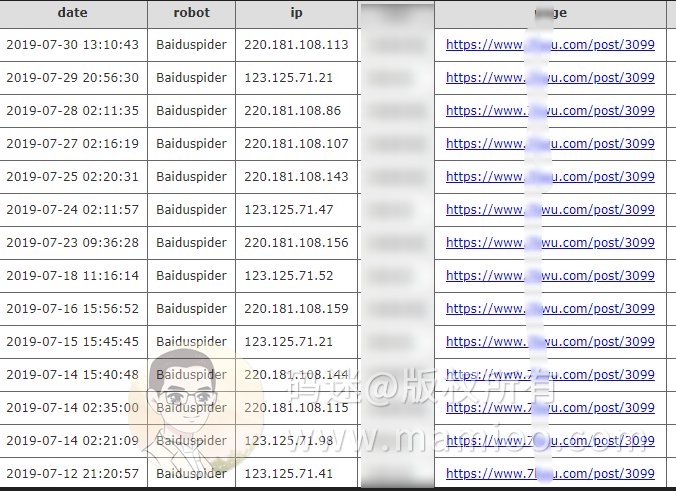
然后隔1-2天,快照必会有更新。比如2019年7月27号220开头蜘蛛访问之后,7月28日快照就更新了。

现象2 首页爬取规律
看下图,mamioo首页的百度爬虫日志,19年6月26上线后,基本上也是123开头的爬虫先行,220爬虫后行,隔天快照更新。

现象3 页面404后的百度爬取规律
码迷人为实验了2个404页面,123开头的爬虫爬取后,一般是2次404之后,不再派爬虫来爬了。
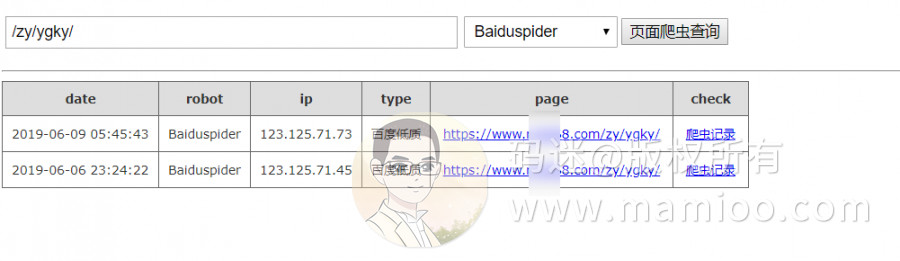
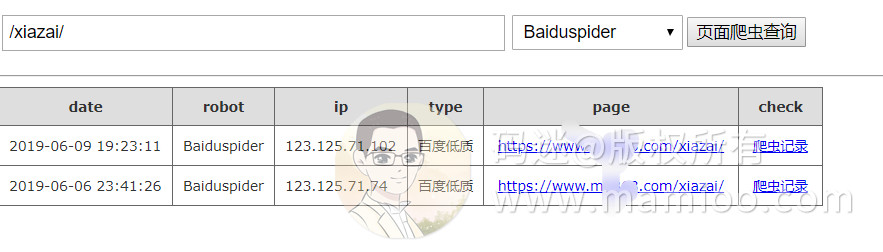
现象4 劣质页面爬取规律
码迷也试验了随机段落混合而成的内容(比如下图妹子不错,但妹子上面的文字很烂),百度123开头蜘蛛抓了一次就再也不抓了,5月11号上线,至今无快照。


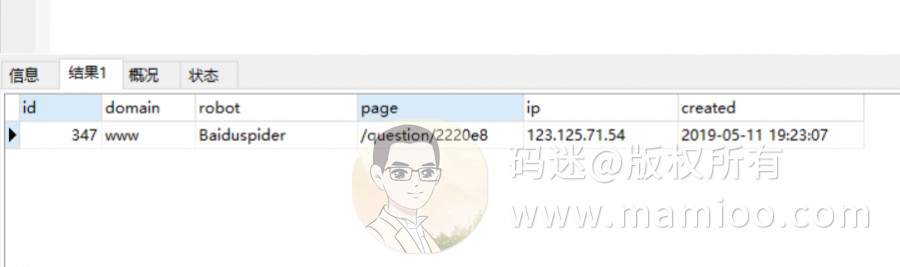
看来百度对随机拼凑的内容还是有识别的。
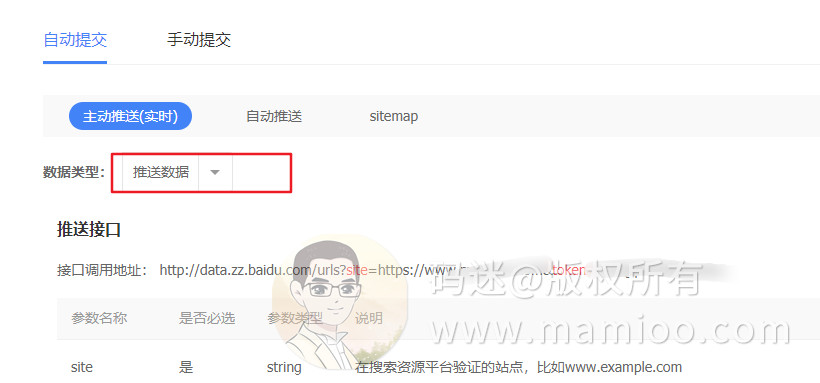
现象5 百度站长主动推送后爬取规律
通过站长主动推送接口推送后,一般7天内就有123开头爬虫到访,如果内容质量较好,会有220开头爬虫二次到访,一般3天内必有快照。
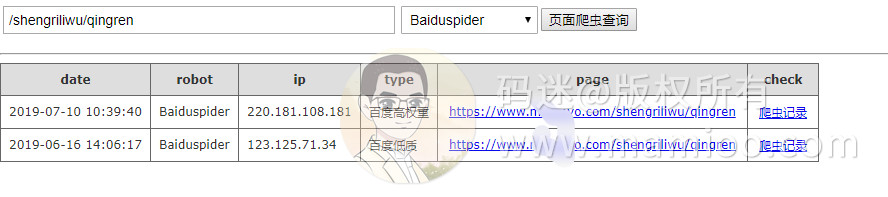
现象6 初次提交仅通过百度主动推送更新数据
码迷有个新站,百度爬虫一直不来,通过主动提交、sitemap、站长反馈都不来蜘蛛,就直接通过更新数据方式进行提交。
当天提交后,次日220开头百度爬虫造访,但3天内不一定有快照,一般需要2个周左右。

现象7 部分百度蜘蛛只爬首页
总结一下百度蜘蛛抓取规律,要不大家都凌乱了。
我是干扰:看了很多采集码迷的文章的,默默诅咒一下吧,码迷真的非常讨厌拿来主义。
规律1
123开头蜘蛛先行,对网页做初步分析,以便为后面正式到网页开展工作做准备。
规律2
220开头蜘蛛一般在123蜘蛛造访后,再次造访。
规律3
如果网页不过关, 220开头蜘蛛不会造访。
规律4
更新页面是220开头直接来造访。
如果大家还是拐不过弯来,码迷把某单页站点的123,220蜘蛛每日访问次数做成柱状图。
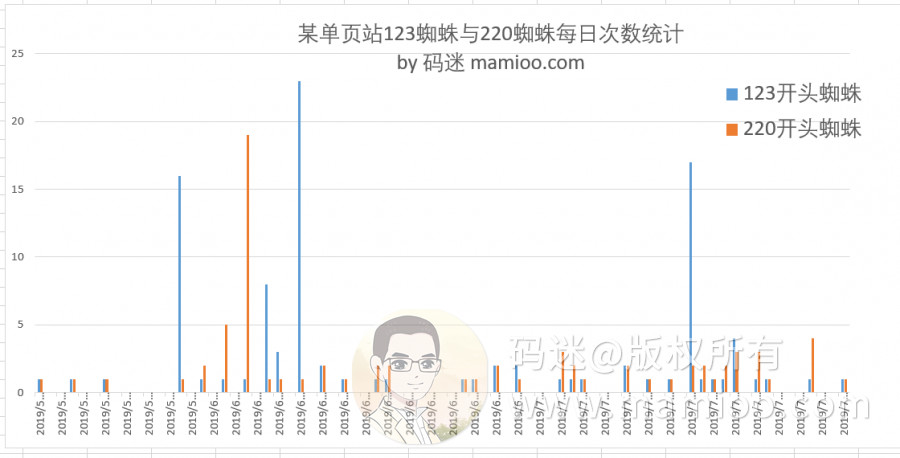
请看下图,蓝色是123开头的蜘蛛,橘色是220开头的蜘蛛。
可以说不管是高质量页面还是低质量页面都有123,220开头的蜘蛛来,还经常成对出现。
好啦,你们是不是明白过来了
结论1:123开头IP是收录蜘蛛
所谓收录蜘蛛是指,百度爬虫造访后,百度后端会通过一系列判定手段,如处理、原创度检测等等,决定是否能够可以收录,是否可以牵引百度快照的蜘蛛到访。
无快照的页面(不收录,无索引)

结论2:220开头的是快照蜘蛛
当快收录蜘蛛检测网页通过了收录标准之后,通过快照蜘蛛生成结构化数据,进入倒排索引。这个时候的网页才有快照,才能被用户搜索到。
结论3:每次快照更新前,收录蜘蛛、快照蜘蛛均有造访
结论4:收录蜘蛛与快照蜘蛛访问比率
一般不超过2:1, 如果收录蜘蛛出现次数远远大于快照蜘蛛,说明网页内容不过关。
结论5 没有什么所谓的提权蜘蛛之说
所谓的高权重蜘蛛是当网页达到快照的收录标准后才会来访问的,不是通过外链直接来的哦。
SEO策略延伸
码迷一直倡导科学的SEO,但是现在绝大部分SEO从业人员只知道每天去写内容,然后就等着内容收录,等着排名。
有些人总提出这样的问题:为什么我的网站一直没收录?为什么有收录了却没有排名?
我们已经知道可以不用通过“site”命令,通过百度爬虫日志,就可以获取网站的收录情况。
所以说,网站爬虫分析系统非常重要!
一个好的网站爬虫分析系统有如下几个功能点:
功能1 整个网站的抓取频率趋势
可以简单了解网站在百度眼中的质量。抓取频率越高,说明百度越喜欢。如果抓取频率一直走低,就要关注近期的内容质量是否变差了。如果频率大幅度降低,查看是不是网址有报错。
功能2 查看收录蜘蛛与蜘蛛比率
只有快照蜘蛛访问过的页面才是有效收录,才能获取百度排名。所以如果很多页面光有收录蜘蛛(123开头的),而快照蜘蛛(220开头)较少,内容一定有问题。查一下内容质量(摩天楼内容助手可以有效解决这一痛点)、内容广告之类是否触犯了百度算法。
功能3 提取重要排名页面的抓取规律
一般情况下,百度会对已有的重要排名页面定期更新快照,123,220开头的蜘蛛定期轮流到访。如果重要排名页面的抓取频率持续走低,说明排名预计会有所下降,尽早查找原因。
另外重要排名页面一般爬虫频率较大,是重要的新内容发现入口,所有如果有相关的新内容,可以在该页面布局,以达到秒收的效果。
如果有编程经验的同学,可以按照以上码迷的想法打造自己的爬虫分析系统。
今天就讲到这里,下一节码迷将对“百度爬虫抓取频率以及优化策略 ”展开探讨,欢迎大家关注。
转载许可
今天就这些,下一节我们开撕百度内部基本流程。微信公众号优质评论前10名将会获得码迷整理的66个百度专利,先到先得。
本系列独家首发于www.mamioo.com,同步发布于公众号”码迷SEO“,未经允许禁止转载采集!违者码迷将诉诸本站法律顾问予以追究相关法律责任!
")
如何刷百度下拉词、推荐词、相关搜索及原理解析")
 快排整站优化提权与百度资源平衡性策略")
 百度快排原理及百度第三代点击排名统计系统简析")
 百度飓风3原创检测算法讲解以及伪原创检测工具")
 从百度网页质量评估浅析个人怎么做流量站(下)")
 从百度专利看百度对网页质量的评估方法(中)")
:谈谈百度对快速排名的打击手段")
评论列表 (0)