本文是码迷SEO内参第六篇,本来想写一篇百度索引相关的文章,昨天忽然看到百度对快排打击手段的算法专利,小小的分析了一下。
码迷之前从未找到过针对快排作弊的百度专利,该专利2019年4月份发布,7月30号审核过了,才1个月多一点,感觉新颖的很。

最近也有几个大佬说快排周期有所变长,甚至有些人觉得是惊雷算法3的节奏。
这份百度打击快排的专利,大家可以到码迷SEO官方QQ群734299959去自行下载。
根据百度的节奏,一般专利出现后3个月就开始初步灰度落地,半年左右扩展放阀。也就是估计今年年底做快排的老师们会淘汰一批了。
本文会根据快速排名原理做一下分析,君不闻飓风算法每次升级都哀鸿遍野呀,所以还是未雨绸缪吧。

相比上一年做快排的老师们都是闷声发大财,今年做快速排名的明显多了起来。只要是个SEO群,里面就有大佬跟迷妹们吆喝“买快排喽,不上首页不要钱”。
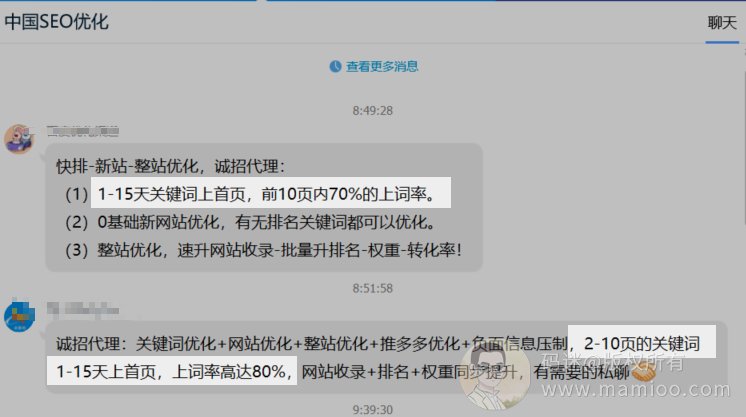
可见百度被技术大佬们嘿嘿嘿的够呛,就连百度论坛里面的一线站长都掩饰不了对百度算法的信心。
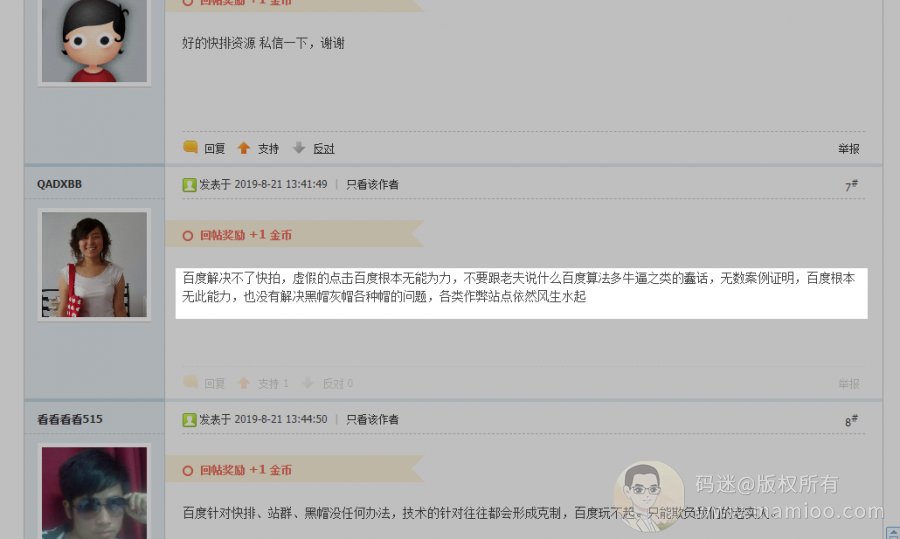
群里面的小伙伴们甚至已经给百度下了定论:百度就是个大垃圾。
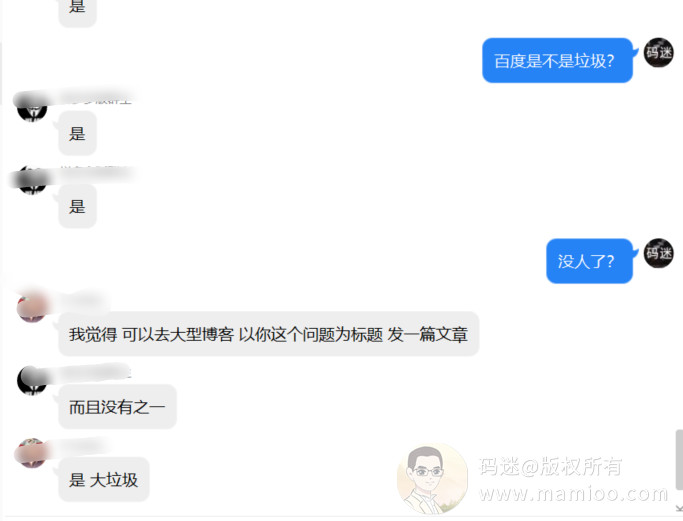
丫的,这年头是个SEO就能做快排的节奏。在这种情况下有些老师也爆出了金句:现在快排泛滥了,这不是好事
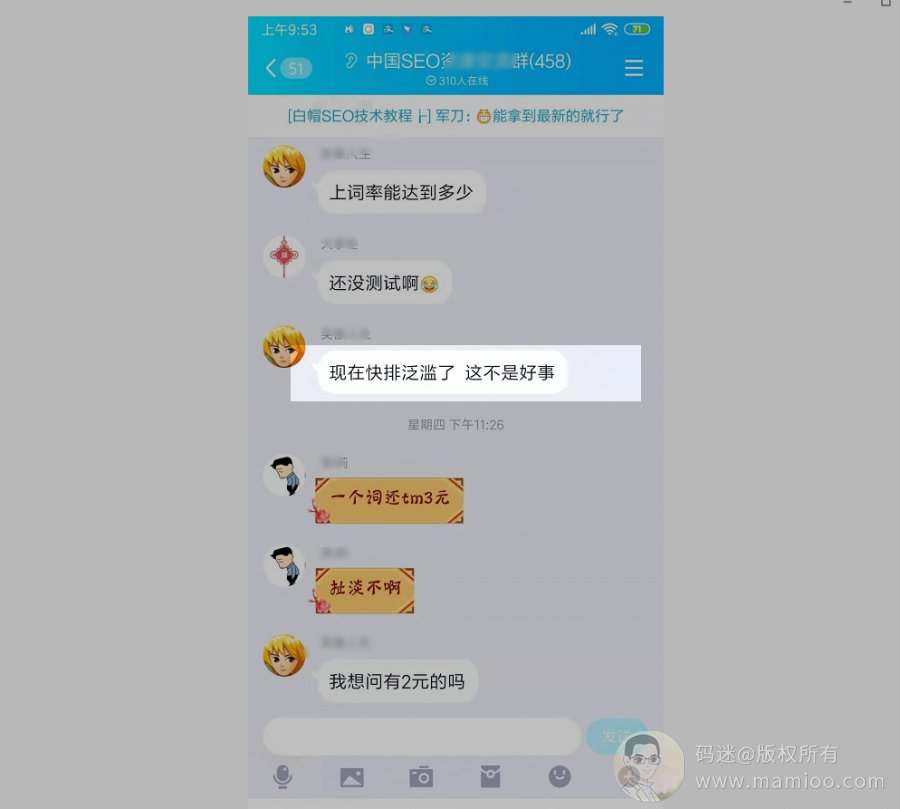
码迷觉得说的真有道理,所谓天道好轮回,苍天到底饶过谁,佛教里面有个概念叫成、住、坏、空。
无论什么SEO技术手段,在生长,维持,颓败中不断演化,最终归为虚无。就像当年的博客外链一样,正当大家搞得如火如荼的时候,百度一个劈叉下马威,把博客外链权重调低,真是“诸行无常”啊,所以我们SEOer应该信佛。。。
我擦,不知不觉跑歪了。
快排原理
很多公众号都讲快排原理,但都讲的什么破原理,把技术手段搬出来讲是什么玩意儿。话说,不识本心,学法无益。
快排的本质是通过模拟点击或者发包(确实有)等技术手段,干扰百度训练结果集,让百度认为你就是最接近用户需求的那个天选之子。
举个例子,老王托媒人找对象,李红娘给老王介绍了6个人老王都不要,请问如果你当老王媒人应该找什么样的人。
1 老王跟A罩杯的某女相亲了5分钟离场
2 老王跟D罩杯的某女相亲了50分钟离场
3 老王跟100斤的某女相亲了100分钟离场
4 老王跟200斤某女相亲了10分钟离场
5 老王跟1米8的某女相亲了3分钟离场
6 老王跟1米6的某女相亲了300分钟离场
那是不是你应该找 36D100斤1米6的姑娘更好些。
回到搜索,百度就是媒人,老王就是用户,200斤的某女就是你的网站,然后你找快排大佬硬生生把老王跟200斤的某女锁在一块度过了N天,百度还天真的认为老王过的很幸福。

快排手段拆解
快排一个字总结就是“装”,谁在百度面前装的像,谁就。
比如我搜索“SEO”,我永远离不开header头里面的参数。
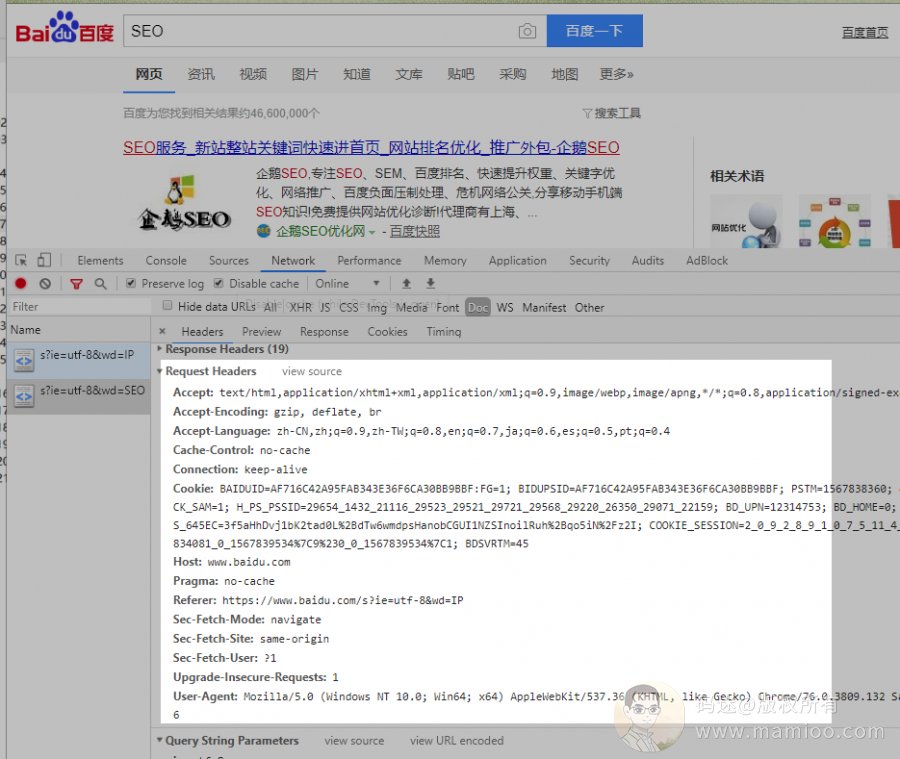
当我点击某个结果网页的时候,除了上面的header头,一堆让人懵逼的参数也要回馈给百度。
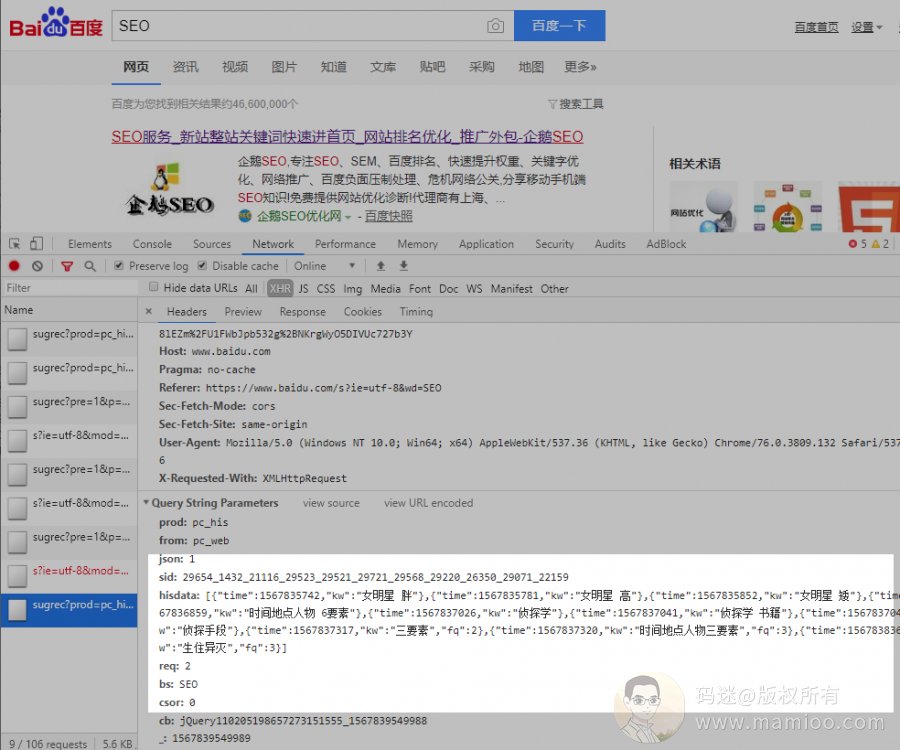
做快排的那帮diao人们,就是在合适的时机,给百度发送这些惟妙惟肖的参数。
但是今天的话题不是教大家做快排,而是分析百度会怎么干翻了那些快排才是重点。
嘿嘿是不是很刺激,这么大的担子落到你身上了,你怕不怕。码迷说不用怕,只要会故事的三要素就行了。
故事的三要素:时间,地点、人物

打击快排的手段1:人物维度
快排一般会模拟两类用户:非登录用户以及登录用户的行为。对于百度,可以搜到如下数据
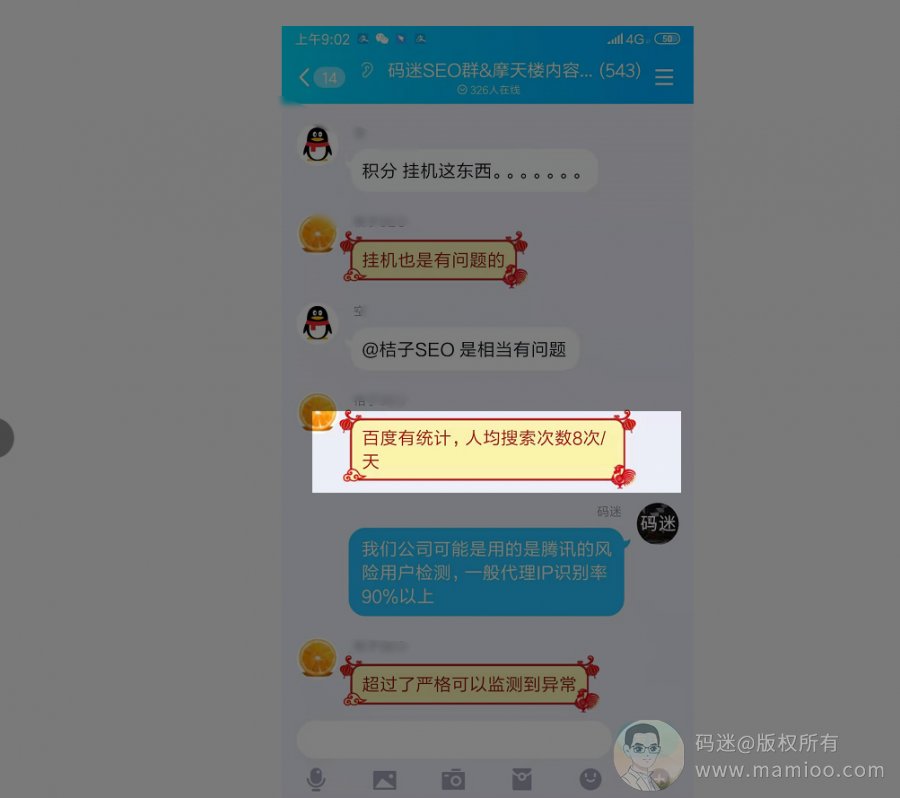
【用户单日搜索次数】
如果某一簇用户人均搜索次数均远远超过了平均数,百度会有所察觉。
【用户行为习惯】
某些快排技术,在做用户滚轮时长、网页下拉的时候,都是固定的值,或者介于一定的范围之内,如果百度能收集到这些数据,也很容易甄别这些异常用户。
【登录用户非登录用户占比】
从站点维度,如果某个站点,访问的非登录用户远远超过登录用户比例,也很容易甄别这些站点。
【临时用户、常驻用户占比】
当我们使用浏览器访问百度的时候,如果是初次访问,会生成一个永久记录的COOKIE,除非清空浏览器缓存,否则这个COOKIE值一直不变。百度也会根据这个COOKIE来记录用户的历史搜索行为。
某些快排手段因为资源限制,不断的清理COOKIE,切换用户。这些生成时间小于某个时长的用户,就叫“临时用户”。
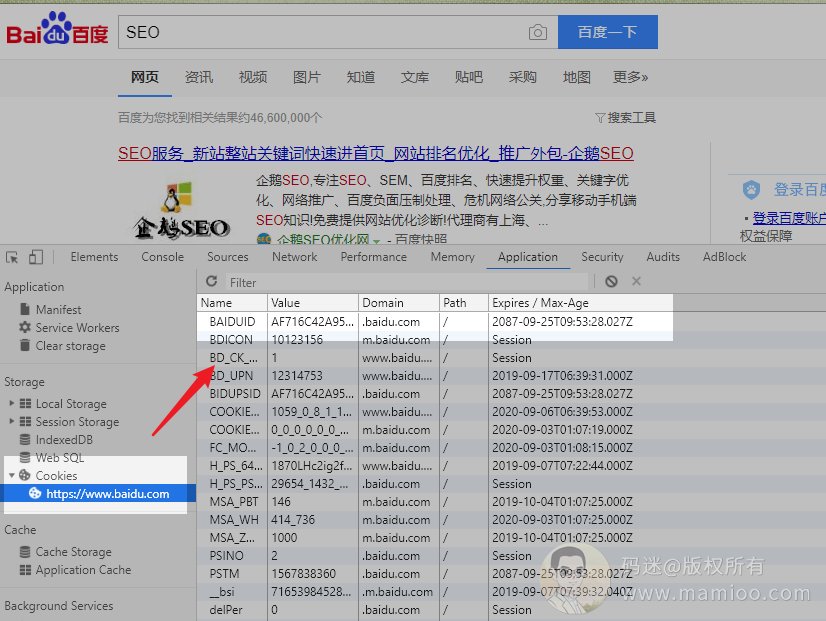
网站点击的临时用户占比过大,也不是正常现象啊。
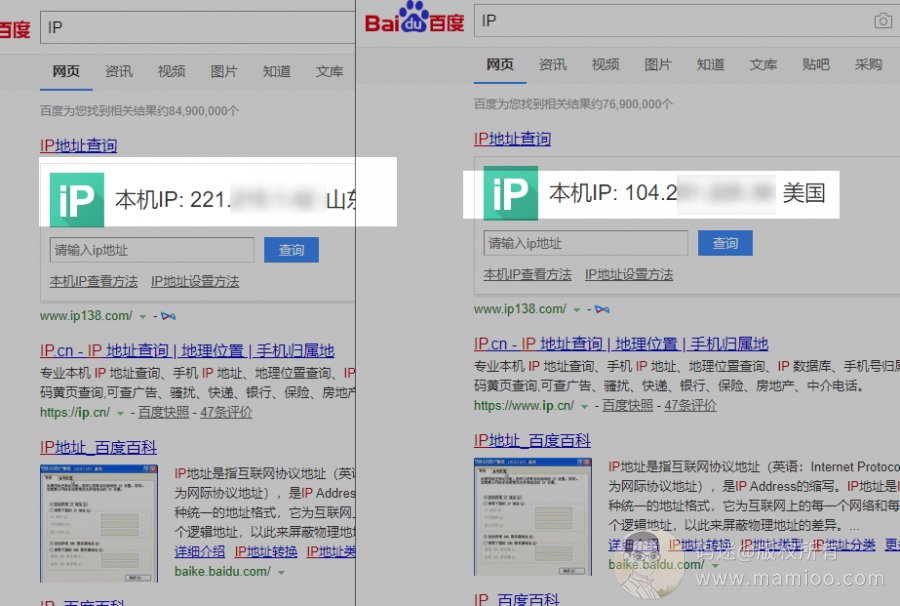
【用户地域穿越行为】
如果某个用户今天12点出现在广东的IP上,12点01分又出现在山东的IP上,13点又出现在美国的IP上,这显然是不合常理的。
这种情况一般出现在那些记录cookie又玩VPS拨号的快排商家中。
打击快排的手段2:地点维度
模拟用户行为离不开产生数据的方法和装置、那么就永远脱离不了IP、MAC、浏览器、客户端、系统类型等等
【单IP搜索量】
在IPv6之前,ip资源永远是稀缺的。如果一个IP每天产生搜索点击超过了平均数,这点在百度惊雷算法2中已经能够识别了。
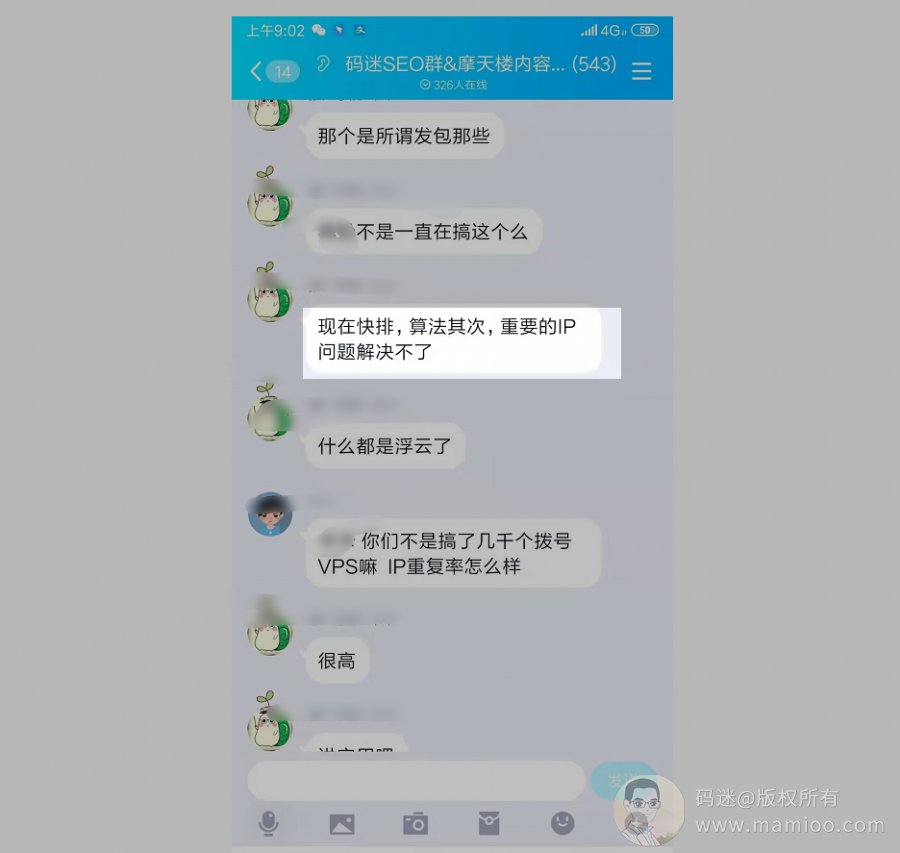
【IP资源有效性】
群里大佬也说,现在即使是VPS拨号重复率也很高。因为现在百度已经可以识别你是IP以及机房IP,所以并非所有的IP有效果。
码迷在百度的同学反馈,在2018年中惊雷算法2已经对快排有所打击,最先打击的手段就是IP资源识别。
但是,IP资源并不是重点,比如一个公司局域网500号人,出口都是1-5个IP,这500号人的点击,百度并不是100%的认为无效。
所以如果大佬有能力跟宽带商合作,即使IP资源不多也非常有效果。
【终端信息熵】
信息熵是什么,一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。因此可以认为信息熵是系统有序化程度的一个度量。
有同学问,这玩意跟快排有毛关系。
无论是发包还是类浏览器模拟,都必须携带header头、cookie等等请求百度服务器。
如果是随机生成的header头,header信息熵必然混乱,信息熵就很高。
如果是固定的header头,header信息熵必然有序,信息熵就很低。
终端信息熵总有一个健康的阀值,根据这个健康的阀值范围,百度也应该甄别一类快排作坊。

【终端分布比例】
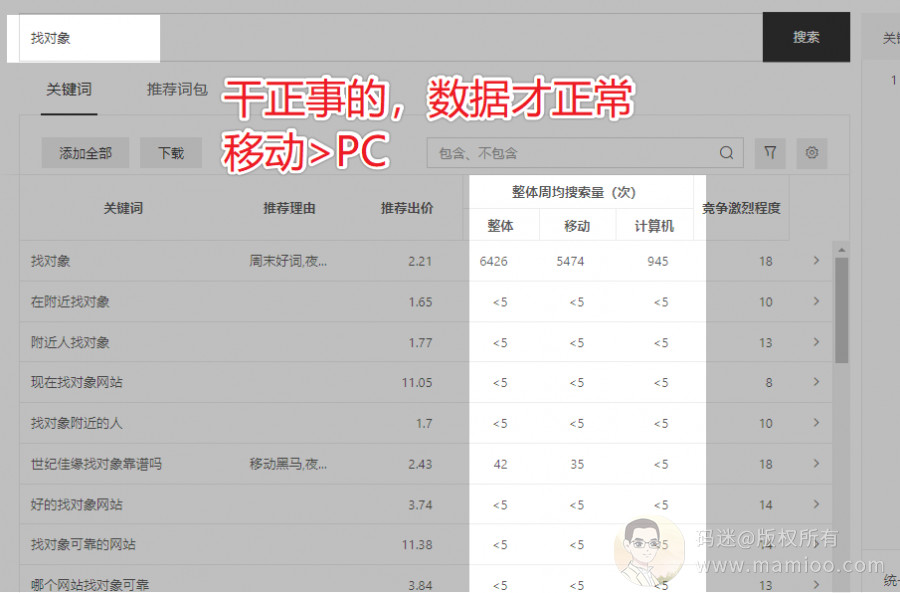
随着4G的普及,其实绝大多数行业都是移动端的访问量多于PC端的,如果某个行业PC端访问量远远高于手机端,那么很可能有快排干扰。
怎么打击,如果你的网站跟行业终端分布比例出路太大,你等着吧。百度肯定是掌握这部分数据的,但是内部协调推进是另一回事了哈哈哈。

打击快排的手段3:时间维度
这块码迷只想到一点,欢迎补充
【用户路径行为分析】
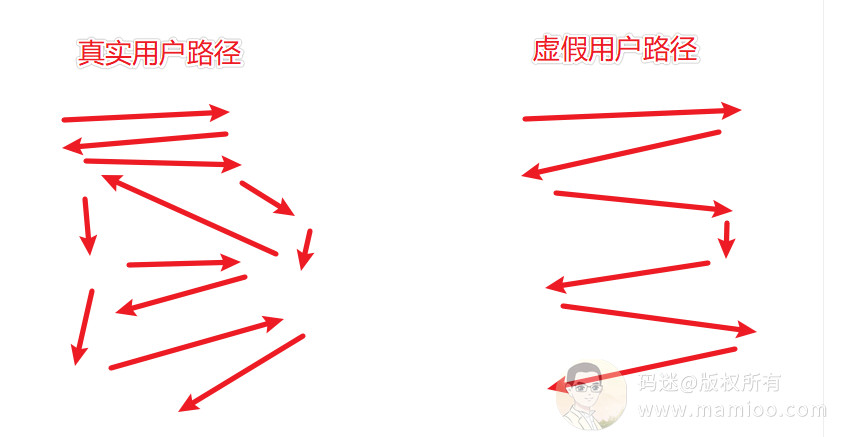
柏拉图说的好啊:我从哪里来,要到哪里去。这是个哲学问题,跟丫的快排有毛关系。举个例子。
真老王今天访问的你的网站,怎么来的,是这样的:
真老王第1步搜:闷气短怎么回事(老王觉得闷气短,搜了一段怀疑是)
真老王第2步又搜:什么症状(看了一下不太像,看到了肺结核的相关资料)
真老王第3步又搜:肺结核症状(看了肺结核症状,我擦,怎么这么像?)
真老王第4步又搜:肺结核那家医院好(终于找到了一家莆田系hospital)
真老王第5步到达你的网站,献出了宝贵的绳命
某快排模拟假老王可能是这样的:
假老王第1步搜:肺结核那家医院好
假老王第2步:打开其他家网站,秒关
假老王第3步:打开你家网站,访问了好长时间
显然,真老王的行为自然性要比假老王 可靠的多得多。
在机器学习中,与用户路径算法相关的向量模型也不少,百度通过真实用户聚类出路由训练集,也可以区分那些简单脑残的点击行为哦。
百度专利解读
百度在2019年4月29提交了打击快排算法相关的专利:《CN201910352770.5 用于处理点击行为数据的方法和装置》
打击的范围:主要是泛域名、寄生虫站点等。(很符合百度特点、先小范围测试哦)

专利使用的算法
机器学习,主要是从【设备标识】、【用户路径行为分析】两个维度,做聚类分析,前期用人工标示黑帽样本集以及白帽样本集,后期开砍~


被打击的对象
鉴于聚类算法的特点,那些点击路径类似于上面案例中“假老王”的访问方法,估计会被打的都不剩。
以后如何做好快排
引用群里大佬的一句话:钱加技术
百度已经开了打击快排的第一枪,码迷觉得百度的打击算法很高大上,毕竟百度的猿们也不是吃素的。
这次专利虽然看起来打击的范围有限,但是从IP终端到用户的访问路径均有提及。百度这次行动,码迷觉得主要目的是黑帽、白帽SEO点击样本的搜集,要不不会存在后端人员做样本库人工标示。
等百度样本搜集完成,经小范围测试后,如果打击效果不错,再灰度扩容。意味着那个时候,如果凭有限的终端资源、不严谨的模拟参数都会被百度检测出来,如果那时候做快速排名的老师们再不做技术资源升级,真的都不剩了。
本系列首发于www.mamioo.com,同步发布于公众号”码迷SEO“,未经允许不可转载。高高低
 百度快排原理及百度第三代点击排名统计系统简析")
")
如何刷百度下拉词、推荐词、相关搜索及原理解析")
 快排整站优化提权与百度资源平衡性策略")
 百度飓风3原创检测算法讲解以及伪原创检测工具")
 从百度网页质量评估浅析个人怎么做流量站(下)")
 从百度专利看百度对网页质量的评估方法(中)")
 从收录现象看百度对网页质量的判定级别(上)")
评论列表 (0)